System Overview
The Helmholtz Knowledge Graph (Helmholtz-KG) infrastructure is a fully automated, cloud-native stack designed to harvest, harmonize, and aggregate the distributed digital assets of the Helmholtz Association into a central semantic representation.
The image below depicts the conceptual data flow in the system as well as the relation of the Helmholtz KG infrastructure stack (middle) to its data providers (left) and users (right).
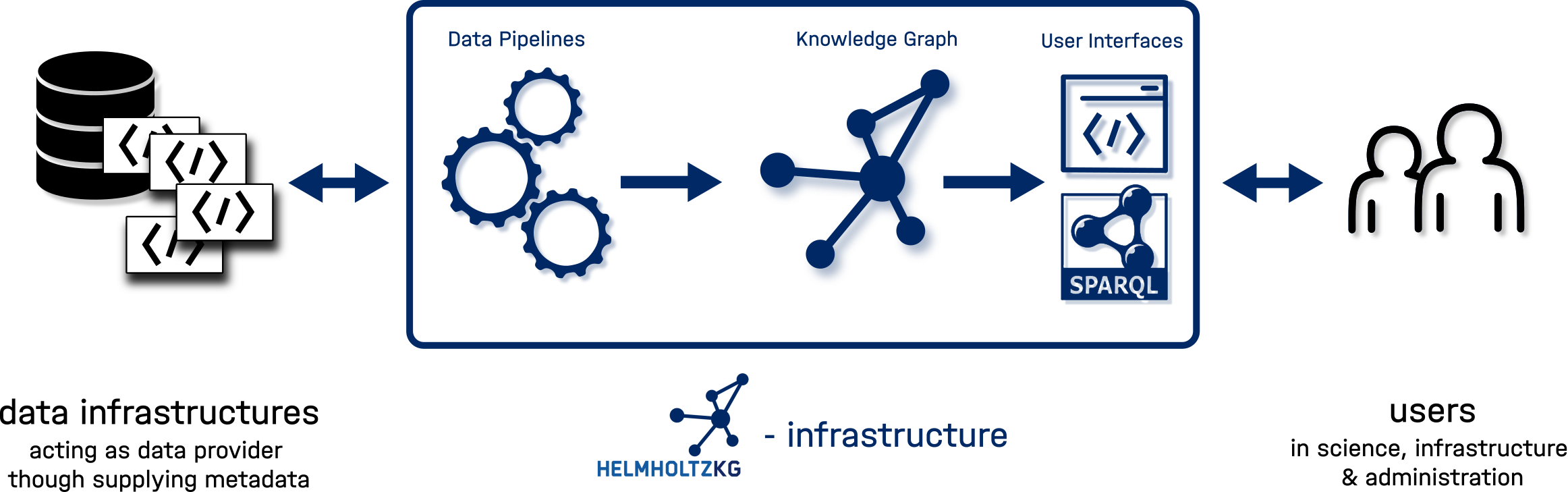
The Helmholtz KG internal infrastructure constist of a three layer stack:
- Data Pipelines that harvest and store data from various resources as well as process, map and validate them in relation to the Helmholtz KG internal data model.
- The Helmholtz KG is the semantic representation of the dataset represented as RDF triples. This is our ground truth source of data.
- User Interfaces & Access Layer make the knowledge graph usable. We deploy SPARQL based interfaces to access the full dataset as well as an elaborate stack of connected technologies that make the graph data accessible in our web interface.
Data Pipelines
- Harvesting: The system collects metadata from [various sources](docs/DataProv/Data Sources.mdx) in their original formats - both in terms of semantics and serialization. Generally, the metadata is harvested through commonly used integration patterns rather than bespoke pipelines. Such pipelines are only deployed and maintained where large quantities of data or multiple endpoints can be harvested through a stable pipeline.
- Storage & Internal Access: A PostgreSQL database stores the harvested raw metadata records. All harvested data records are assigned a globally unique PURL using PIDA. Within our infrastructure the data is served for further processing through a Data Storage API. This is also made available externally to track provenance of the entities in our graph.
- Mapping & validation transforms raw data into a unified semantic graph. It is performed through pydantic schemas that map and validate the data against the Helmholtz KG internal data model. During mapping, all graph nodes are enriched with globally unique identifiers. If there is none provided with the source data, a hash is generated based on the information within a given record which is then appended to our KG namespace (
purls.helmholtz-metadaten.de/helmholtzkg/hkg:*). The generation of hashsums is further varied based on the likelihood of uniqueness for a given semantic type (e.g. stricter for persons than for institutions). The link to the original provenance record is encoded directly within the graph viaPROV:has_provanance.
The Helmholtz KG (Semantic Data)
- Primary Triple storeStore: Facilitated through a wrapping-routine the data is injected into OpenLink Virtuoso. This triple store serves as the "Source of Truth" for the Knowledge Graph. It is optimized for bulk loading and complex semantic relationships.
- SPARQL Performance Mirror: A snapshot of the Virtuoso graph is regularly dumped into QLever, a high-performance engine optimized for fast SPARQL read and query operations.
User Interfaces (Search & Discovery)
- Human readability: For human readibility and user-friendly search experience, we provide a comprehensive web-frontend of selected graph parts. To do this the graph triples are indexed into a search engine (OpenSearch). To do so, a specialized indexer queries the graph and maps complex relationships into a structure optimized for full-text search and faceted browsing. Then the Helmholtz KG Web UI interacts with the OpenSearch index to provide the final discovery interface for users.
- Machine readibility The full dataset can be explored via two distinct [SPARQL endpoints}(../new_03_Use/SPARQL.md): Qlever as a high-performance and rapid exploration option, Virtuoso as a production-grade stability and interoperability interface
Infrastructure & Deployment
The entire system is hosted at the Jülich Supercomputer Centre (JSC) Cloud within Forschungszentrum Jülich.
- Platform: Running on Kubernetes (K8s).
- Automation: Deployment is managed via GitLab CI/CD and FluxCD, ensuring a GitOps approach to infrastructure.
- Orchestration: Apache Airflow manages the end-to-end data lifecycle, triggering a full pipeline execution every week.